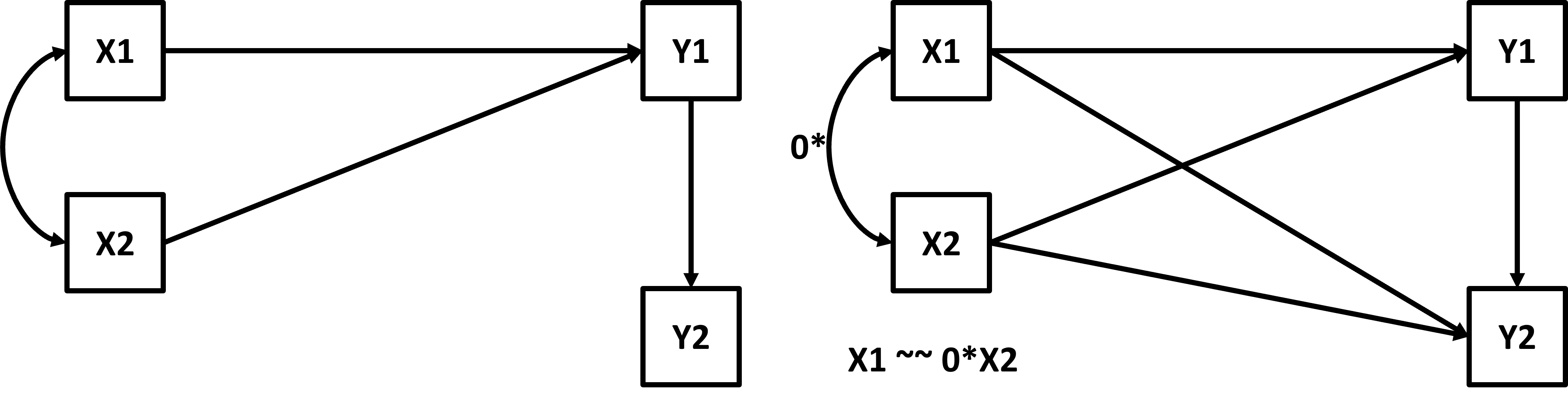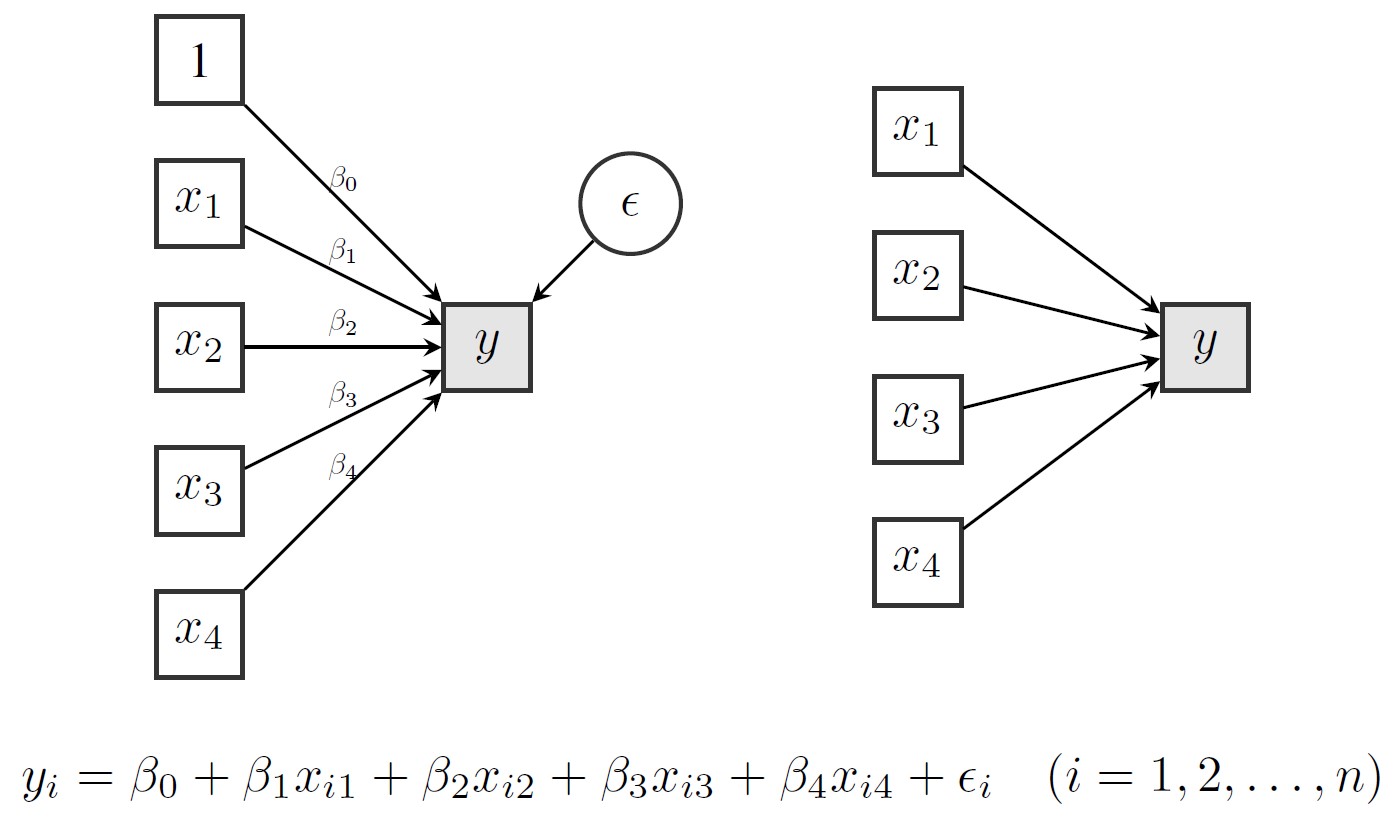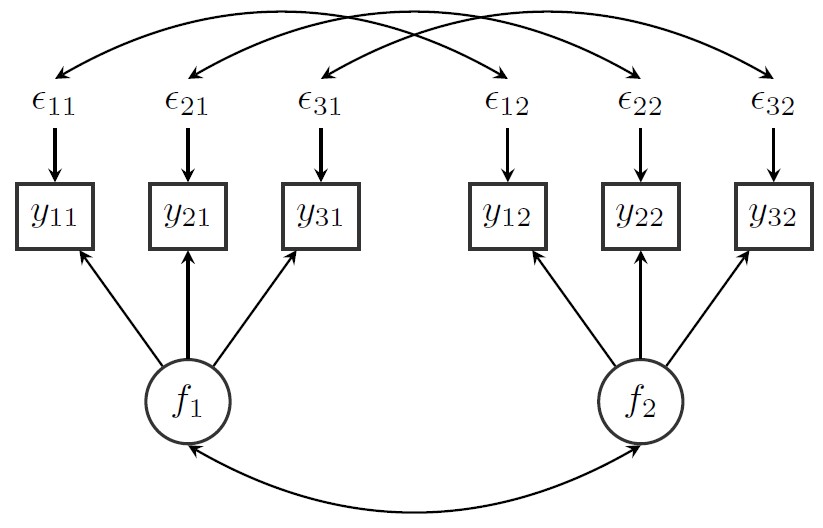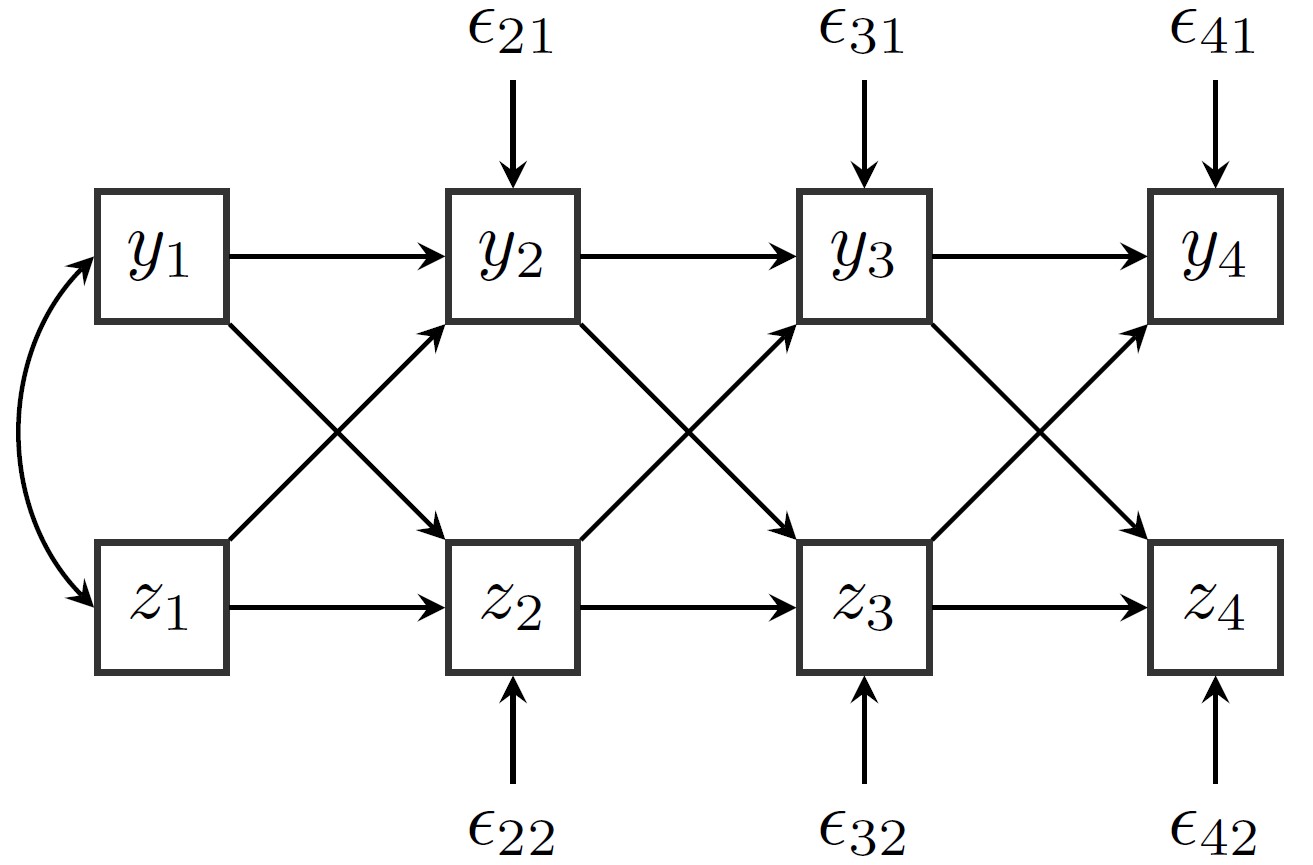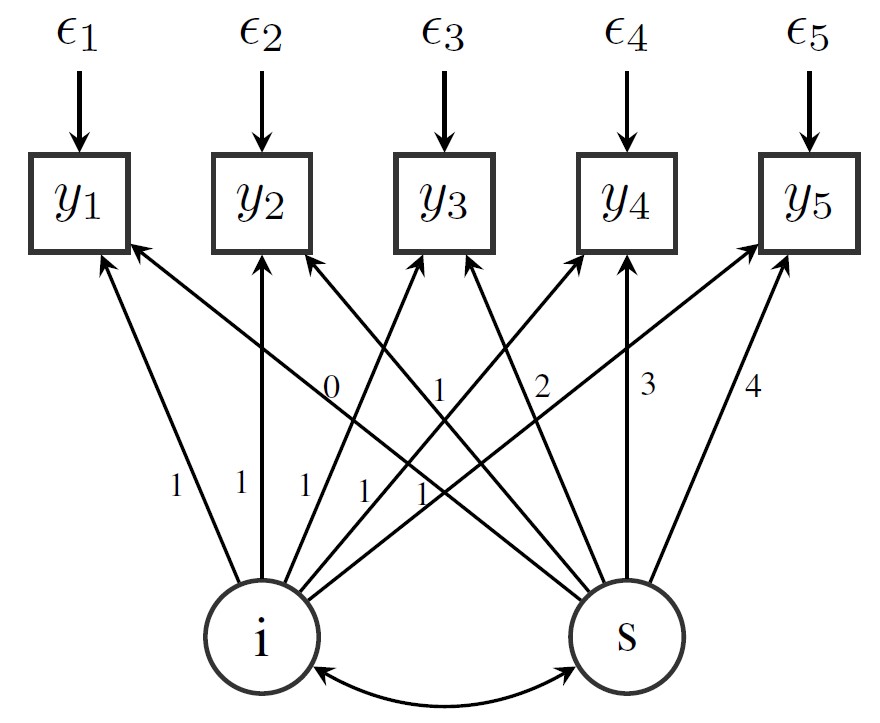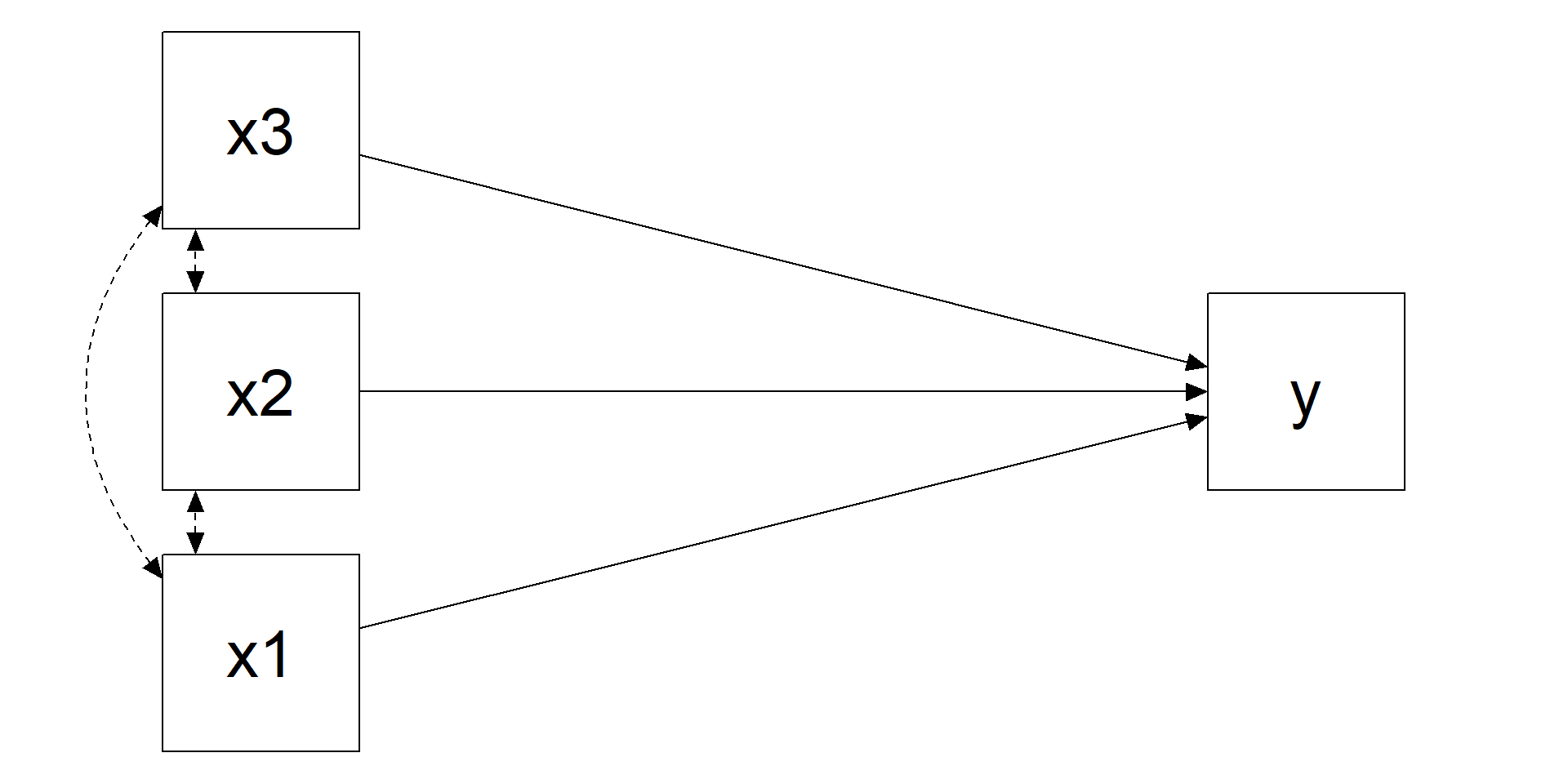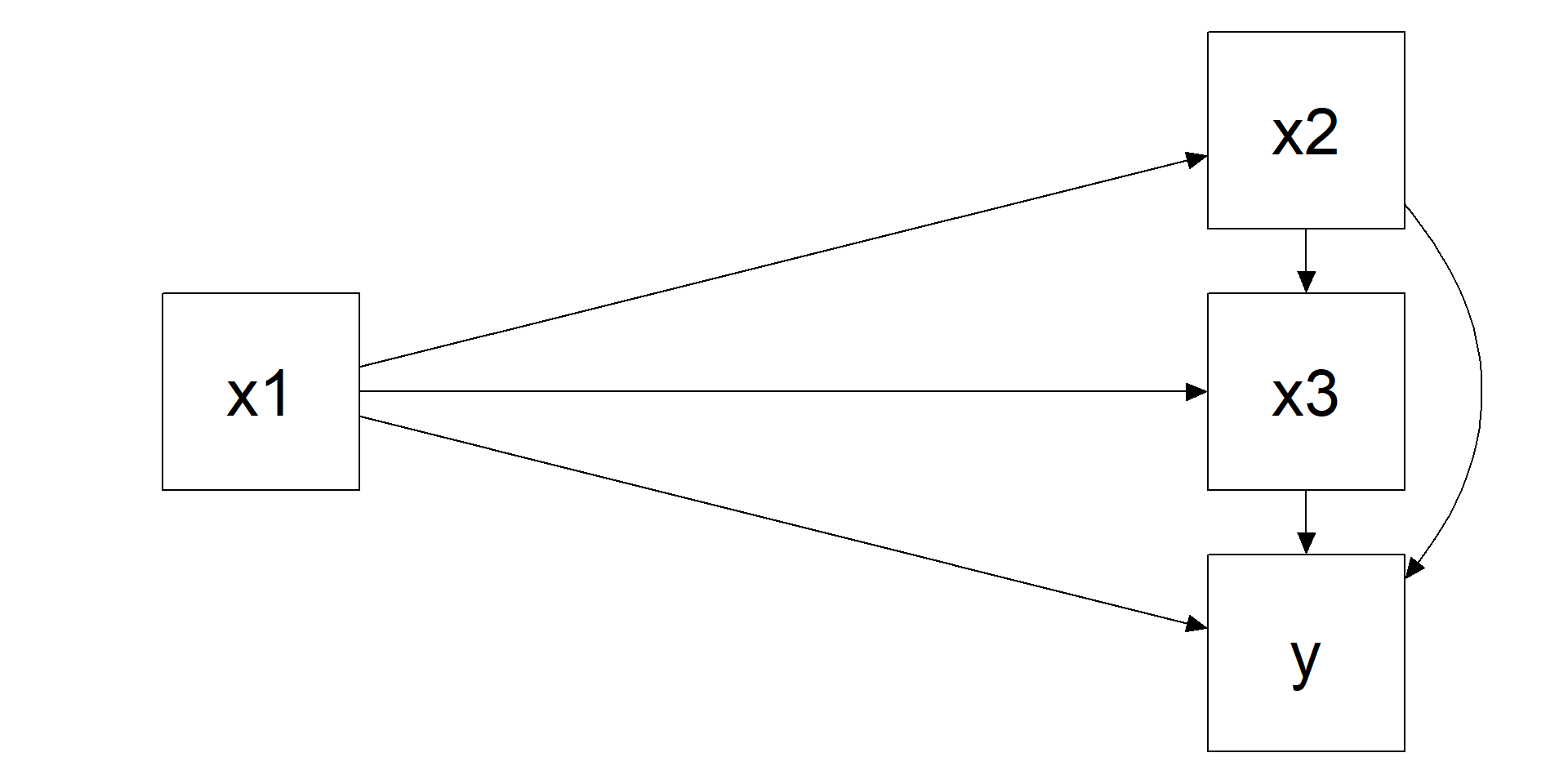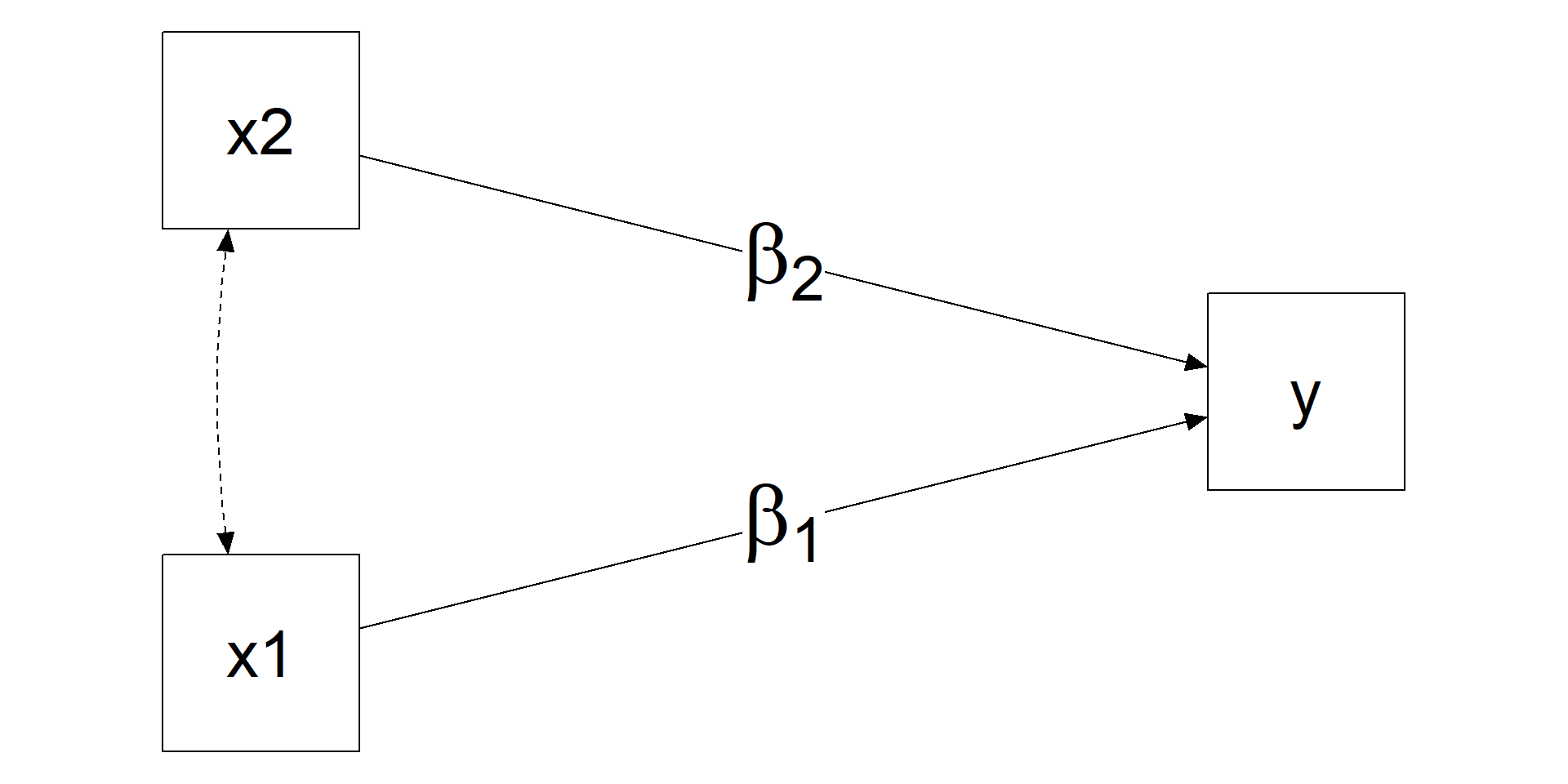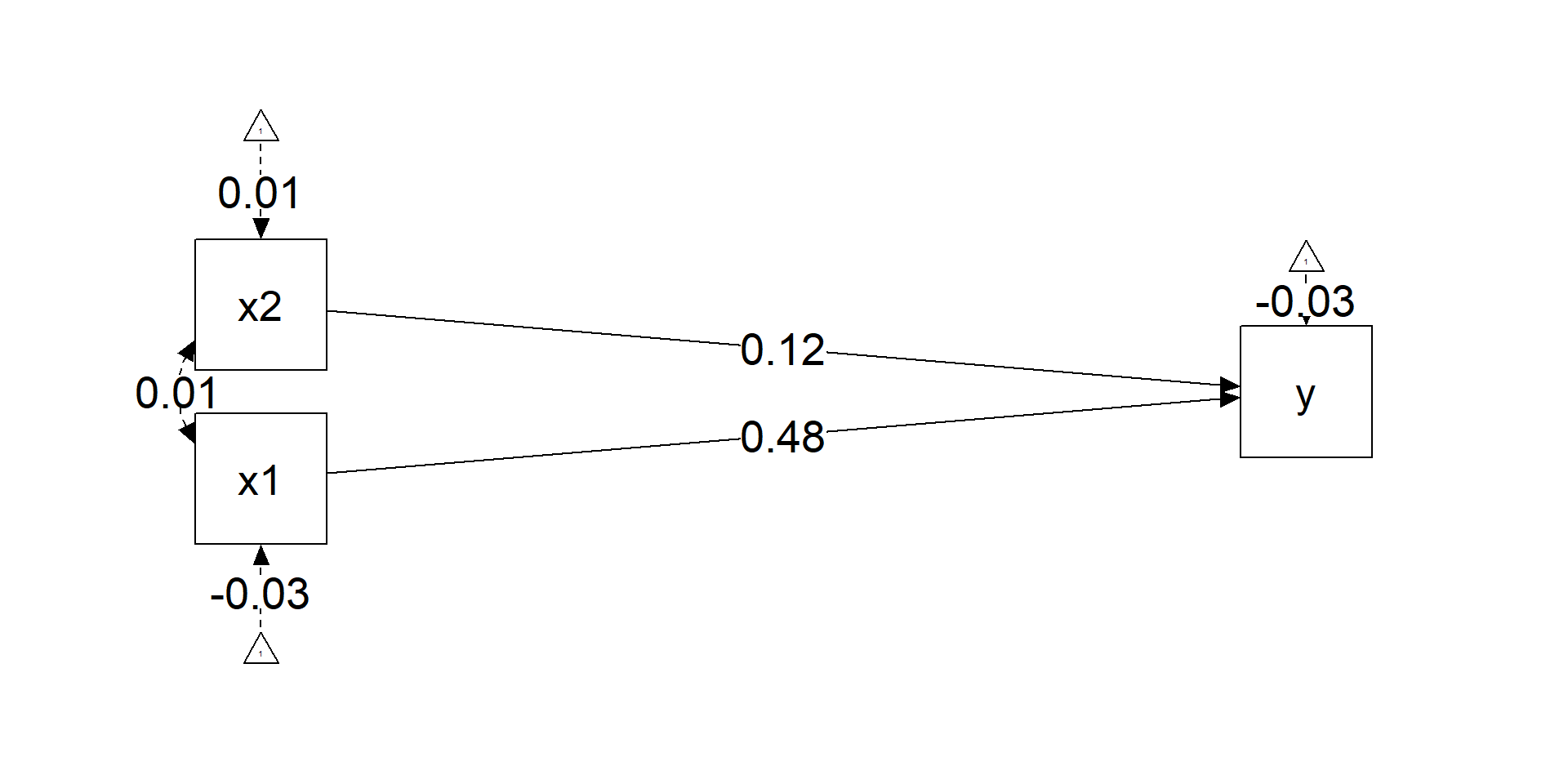
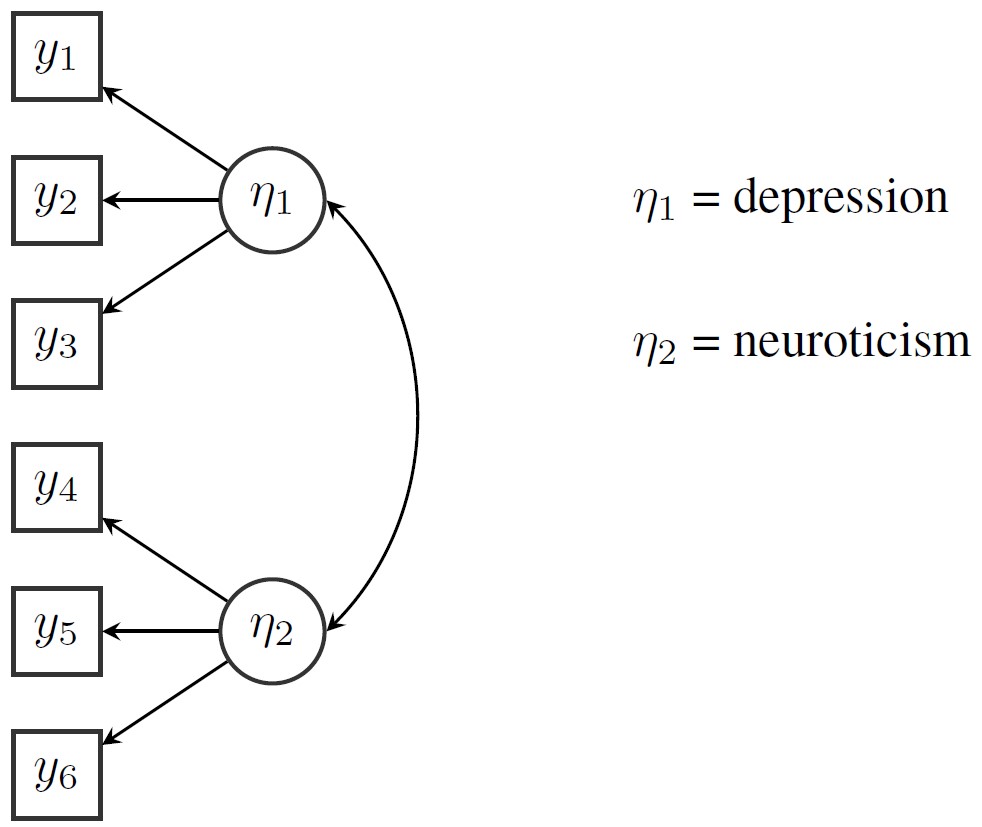
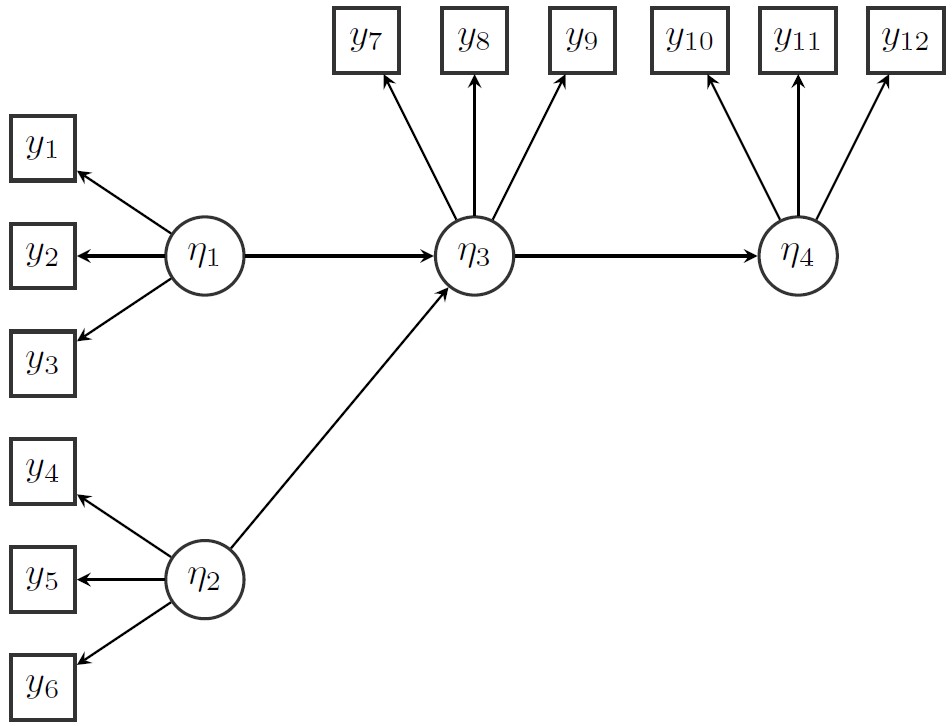
options(digits = 2)
cov(PoliticalDemocracy[1:7]) y1 y2 y3 y4 y5 y6 y7
y1 6.9 6.3 5.8 6.1 5.1 5.7 5.8
y2 6.3 15.6 5.8 9.5 5.6 9.4 7.5
y3 5.8 5.8 10.8 6.7 4.9 4.7 7.0
y4 6.1 9.5 6.7 11.2 5.7 7.4 7.5
y5 5.1 5.6 4.9 5.7 6.8 5.0 5.8
y6 5.7 9.4 4.7 7.4 5.0 11.4 6.7
y7 5.8 7.5 7.0 7.5 5.8 6.7 10.8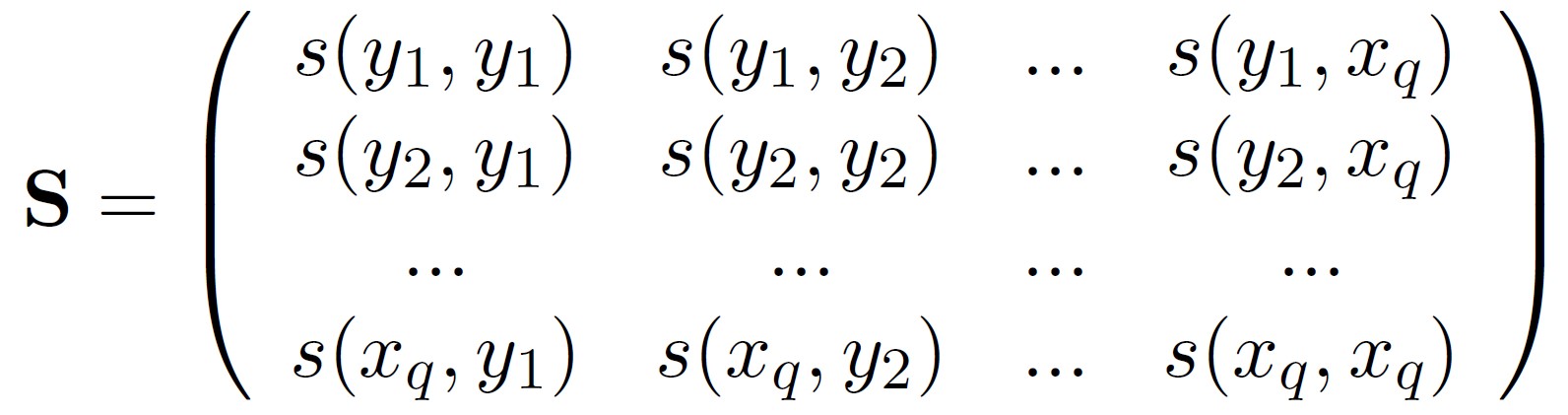
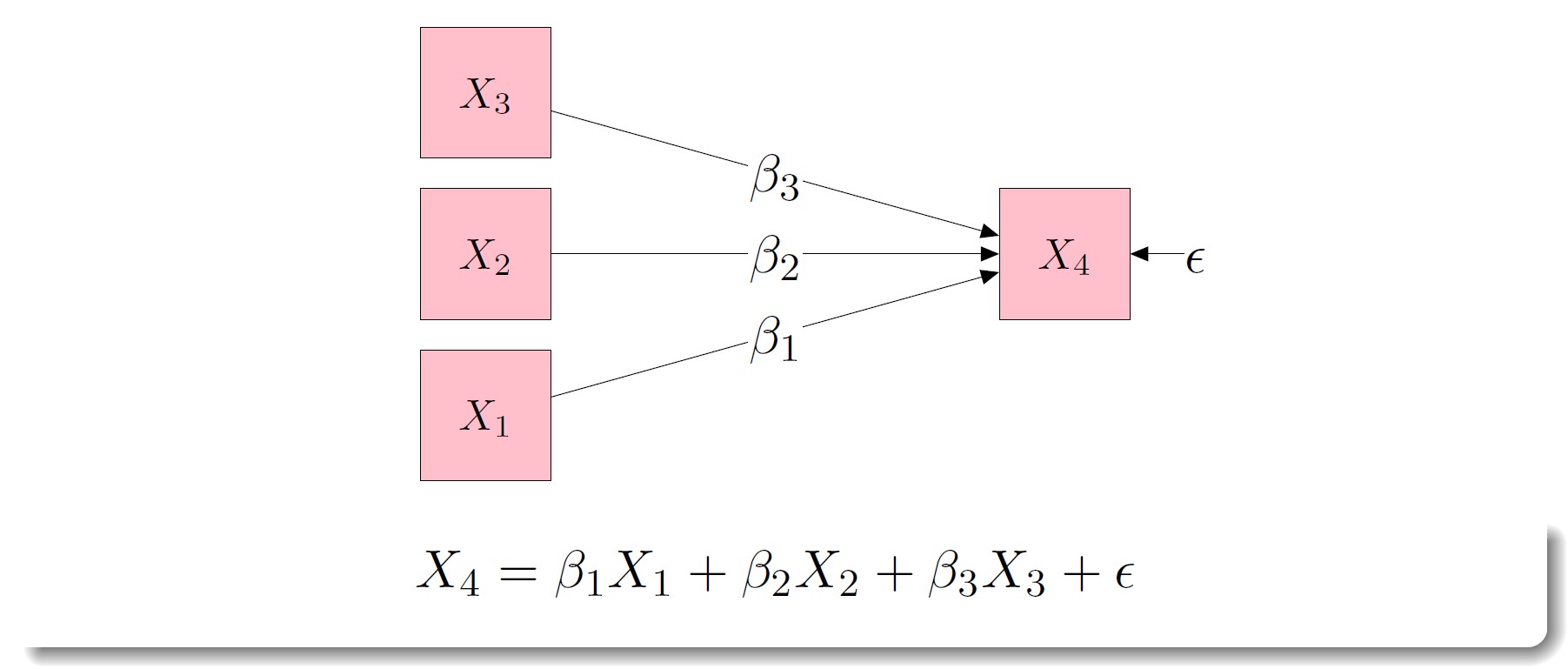
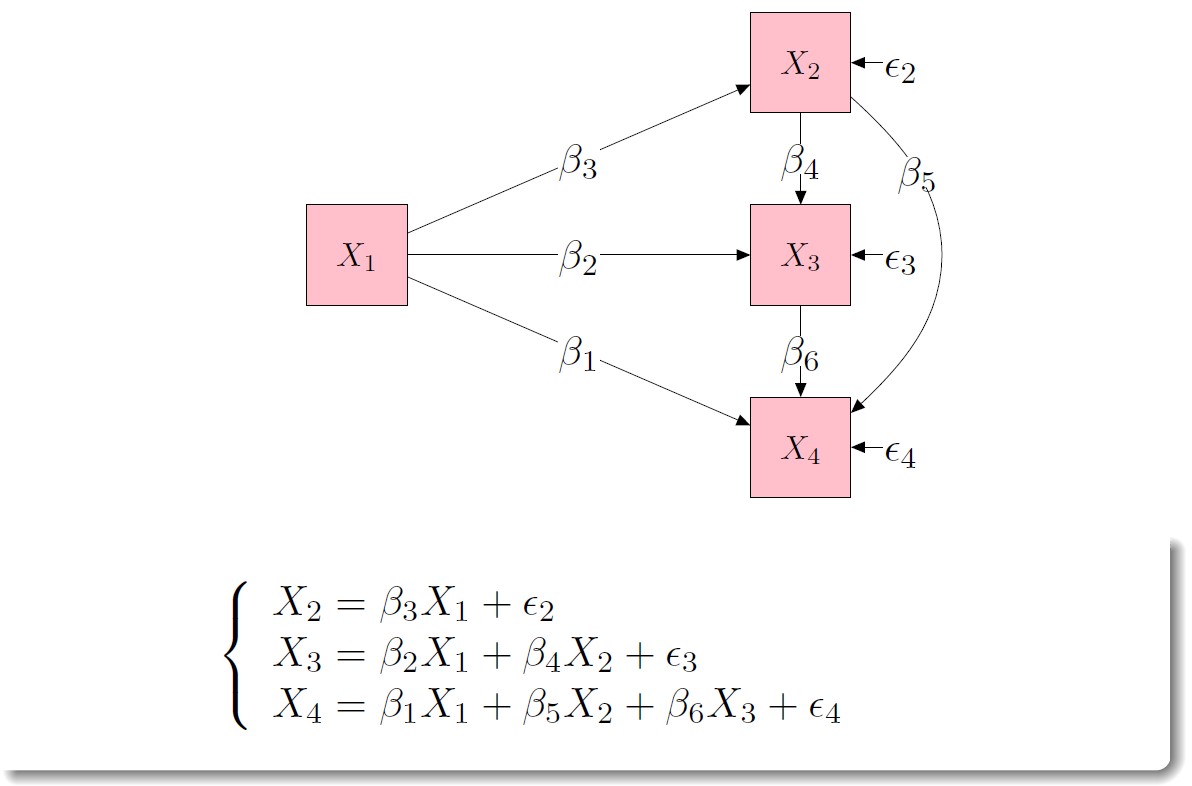
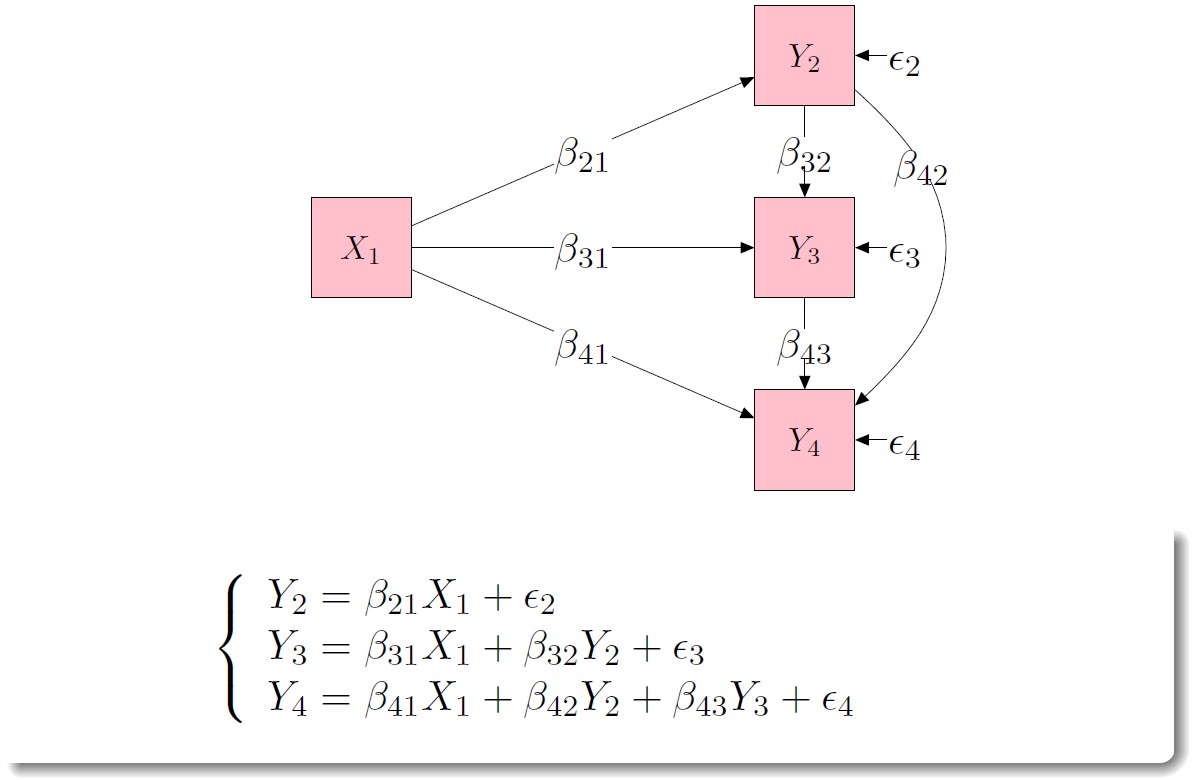
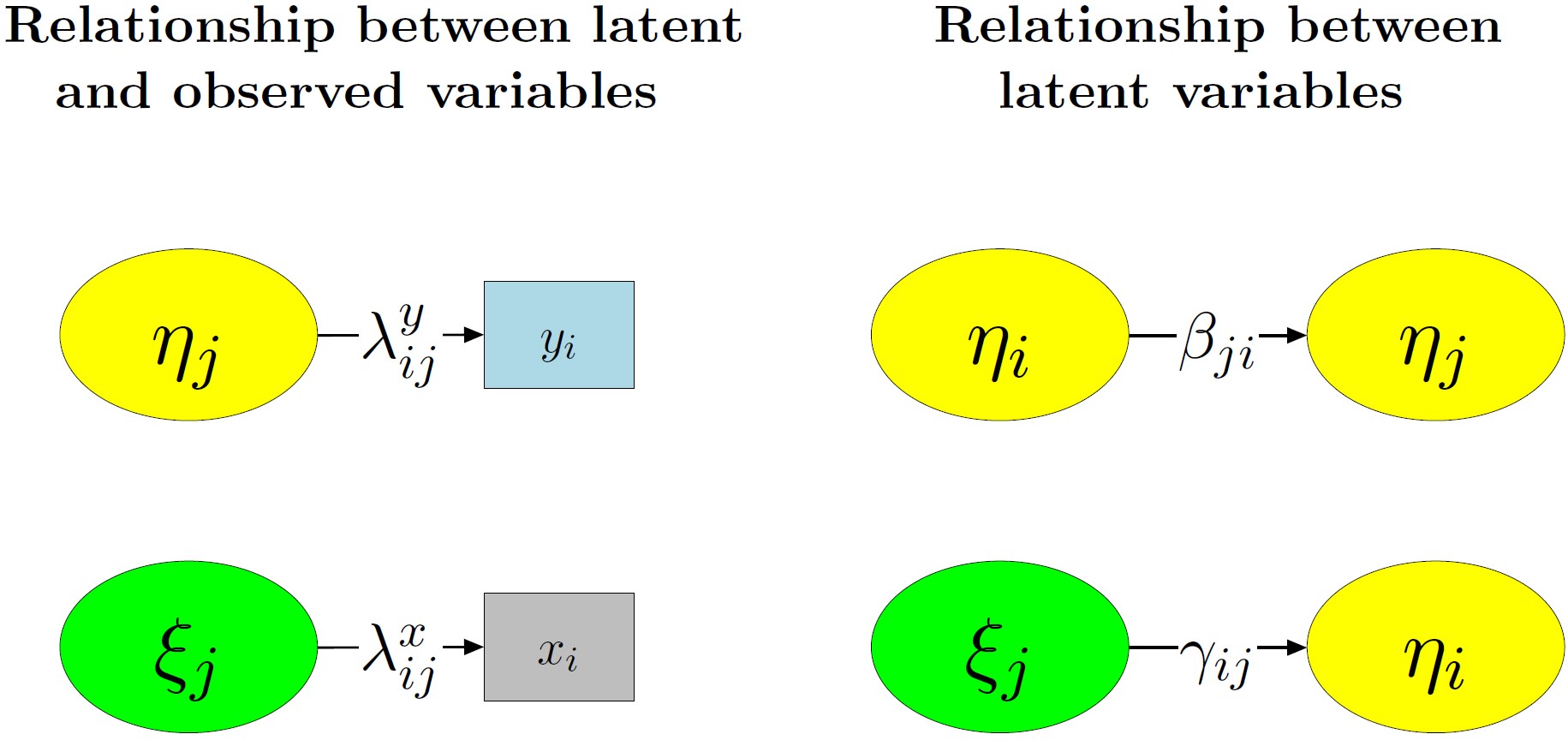
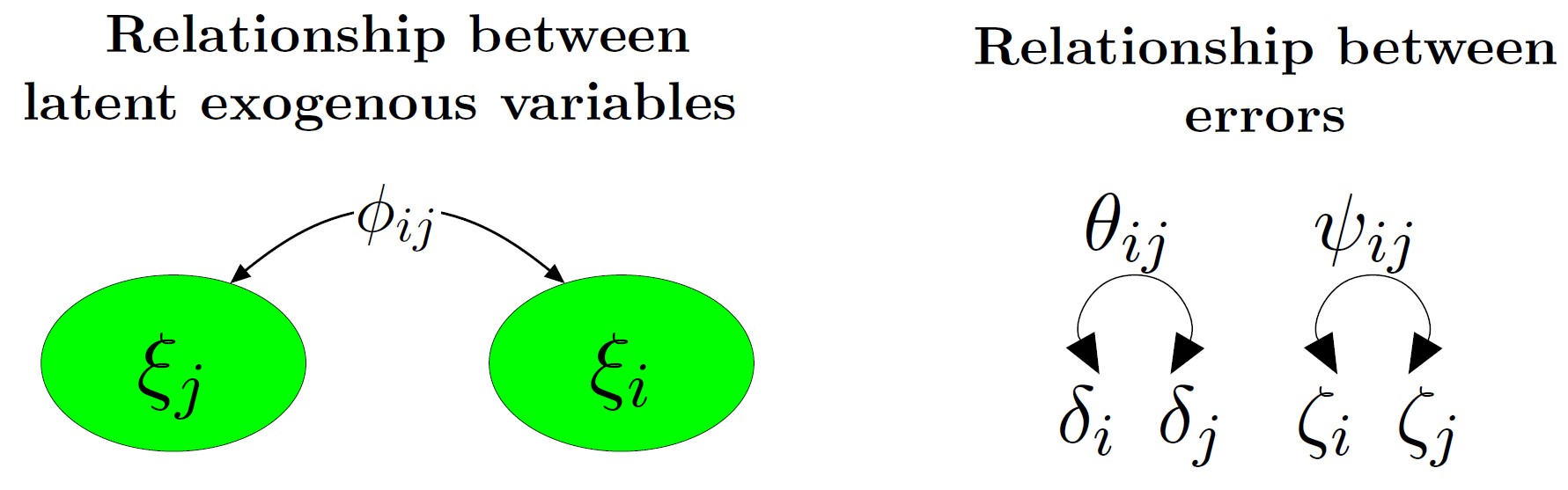
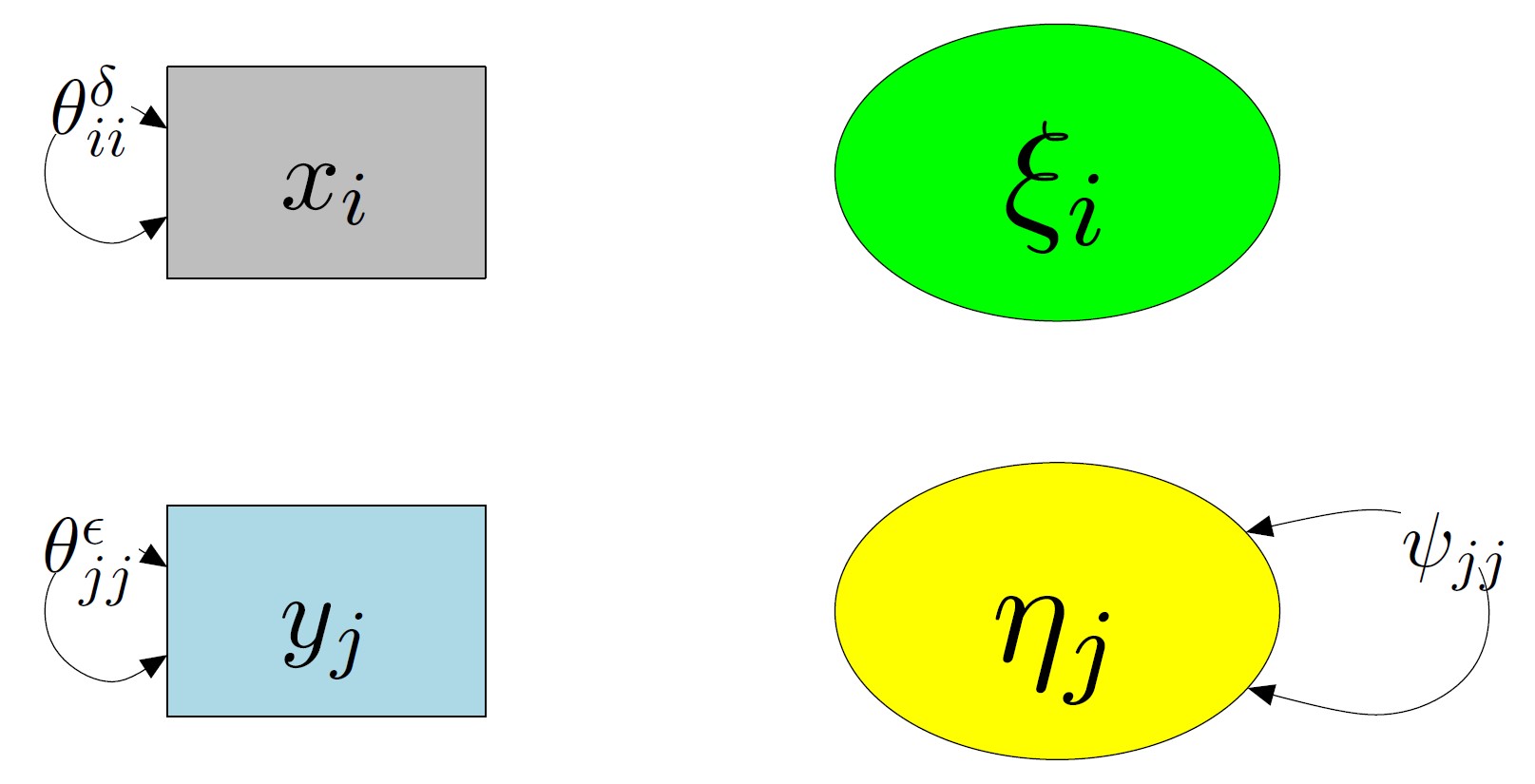
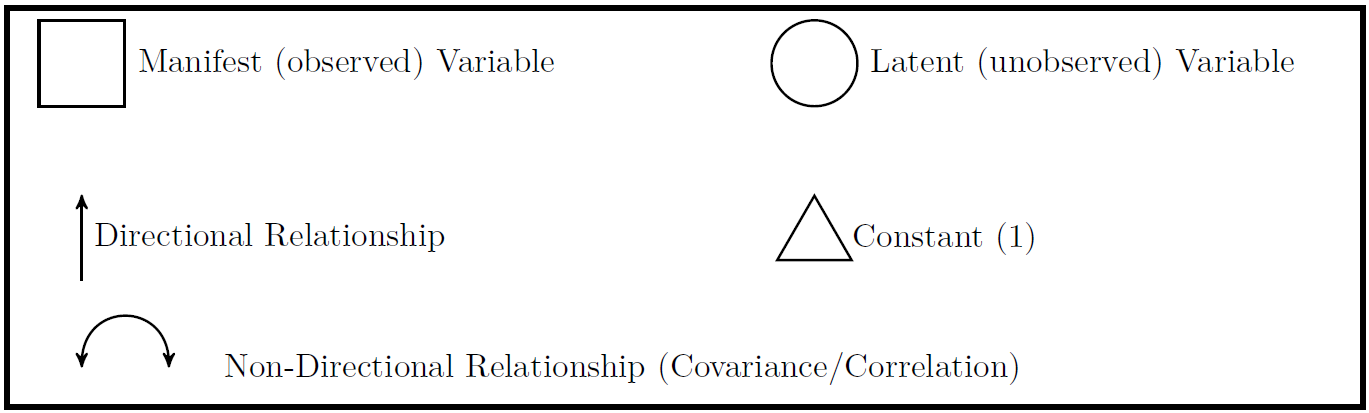
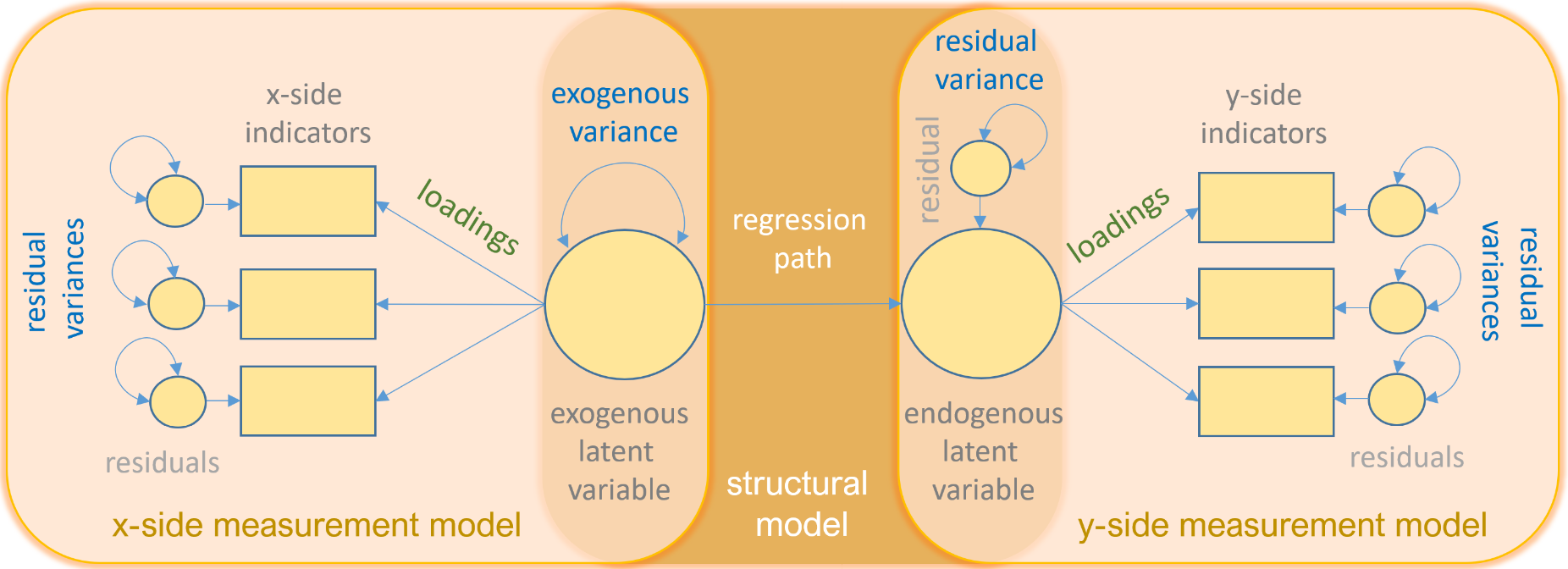 img credits to dr. Johnny Lin (youtube
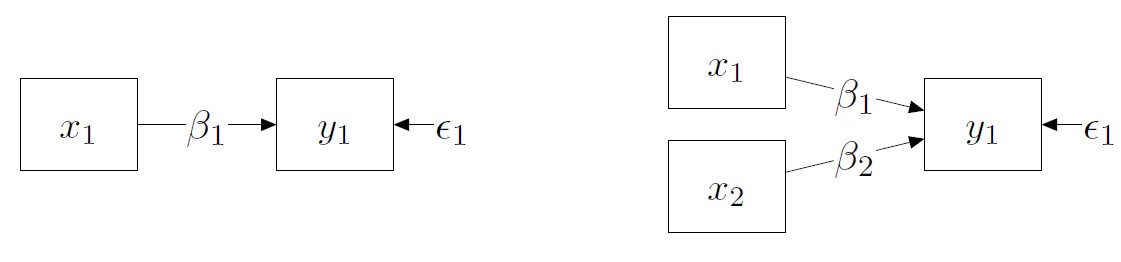
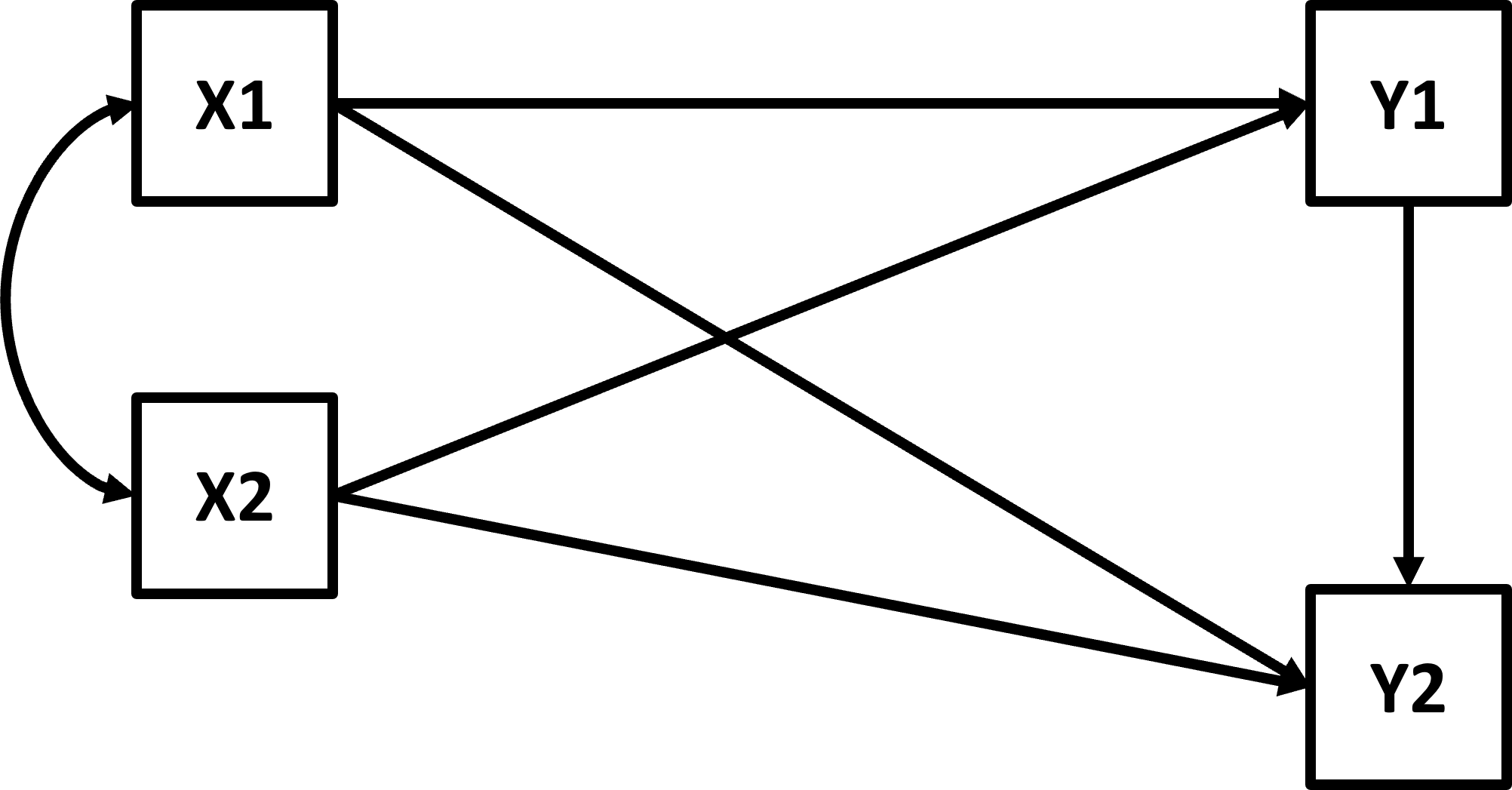
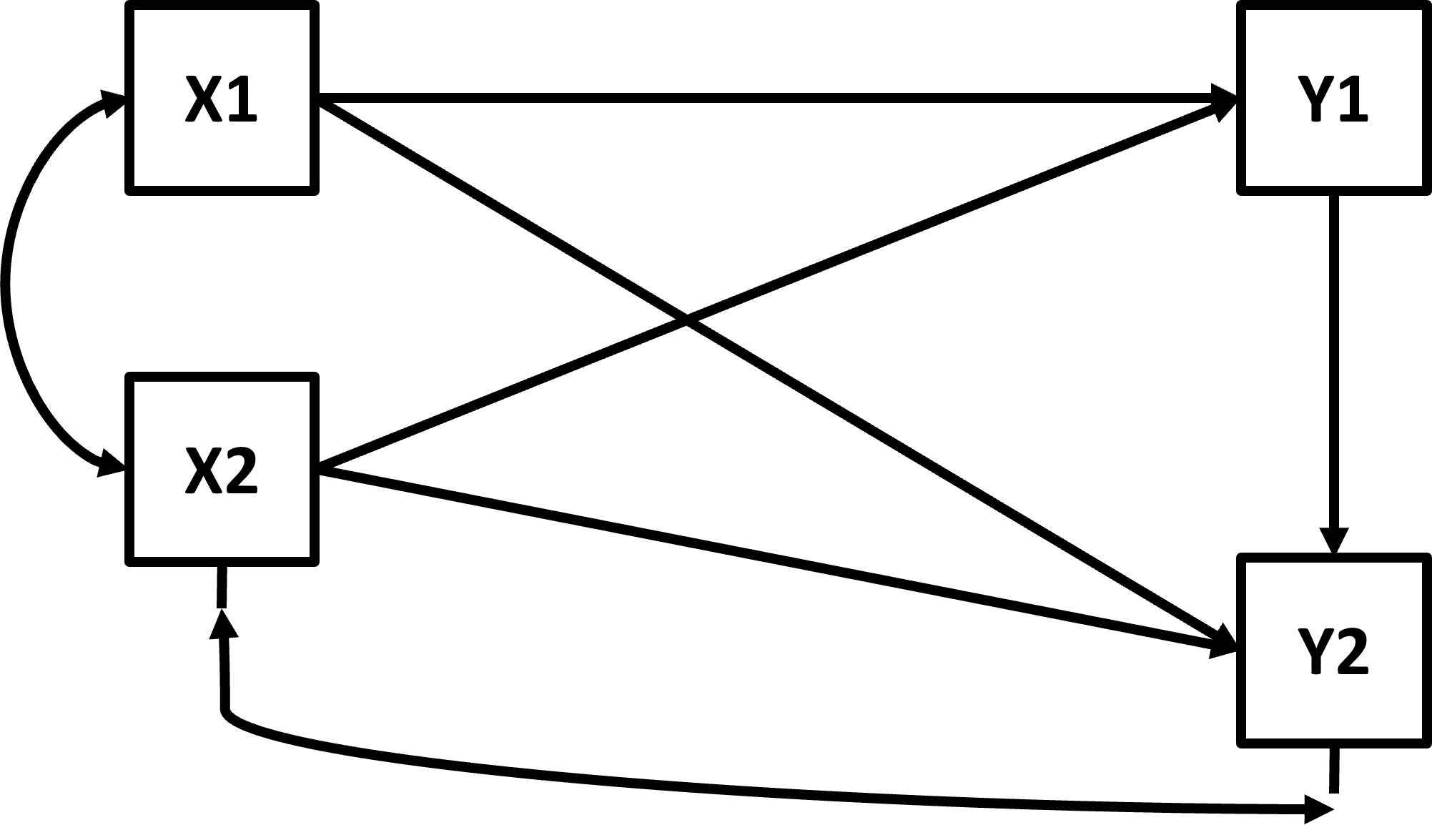
img credits to dr. Johnny Lin (youtube