m <- '
F1 =~ y1 + y2 + y3
F2 =~ y4 + y5 + y6
F1 ~~ F2 # factor covariance (oblique)
'
fit <- cfa(m, data = dat) # or sem(m, data = dat)
summary(fit, standardized = TRUE, fit.measures = TRUE)CFA: measurement models, identification, reliability
From items to constructs (measurement-first)
Factor analysis
Important
Factor analysis models believe that a small number of latent dimensions explain systematic covariance among many observed variables.
Warning
PCA is not a factor analysis. It does not assume the ‘existence’ of any latent trait.
Exploratory Factor Analysis (EFA)
EFA: discover a plausible loading pattern.
- loadings are “free” (rotation chooses a representation)
- useful for exploration and item development
- weak theory → eavily exploratory
Confirmatory Factor Analysis (CFA)
CFA: test a specific measurement hypothesis.
- you specify which loadings are zero vs free
- you can impose constraints (equal loadings, orthogonality, hierarchies)
- fit and diagnostics evaluate a theoretically constrained model
The implied covariance (the single most important equation)
For a standard CFA with latent covariance \((\Phi)\) and residual covariance \((\Theta)\):
\[ \Sigma = \Lambda \Phi \Lambda' + \Theta \]
This is why:
- loadings \((\Lambda)\) and factor correlations \((\Phi)\) jointly shape observed covariances
- correlated residuals (off-diagonal \((\Theta)\)) are extra covariance not explained by factors
Lambda: matrix of loadings
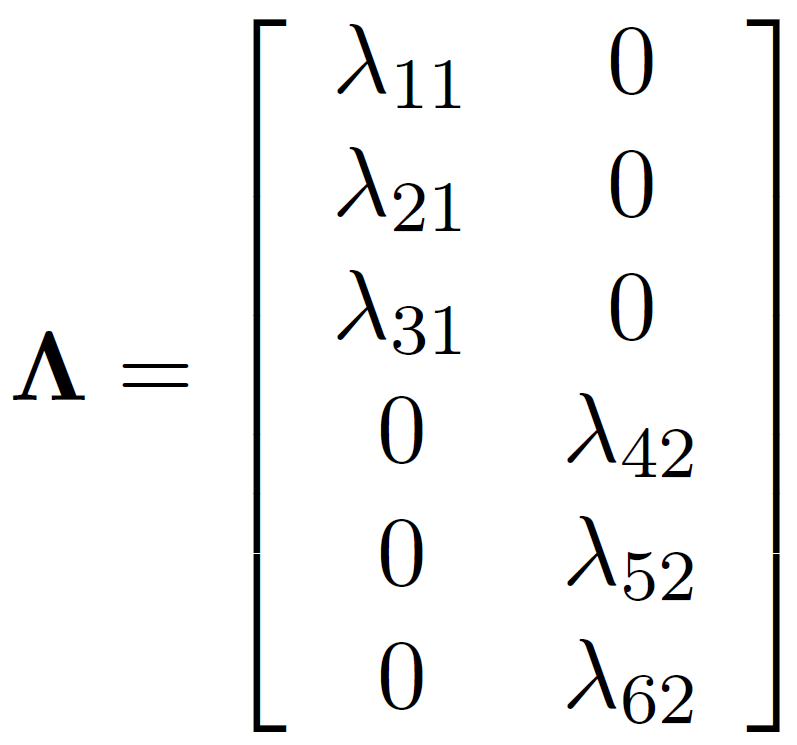
Phi: latent variance-covariance matrix
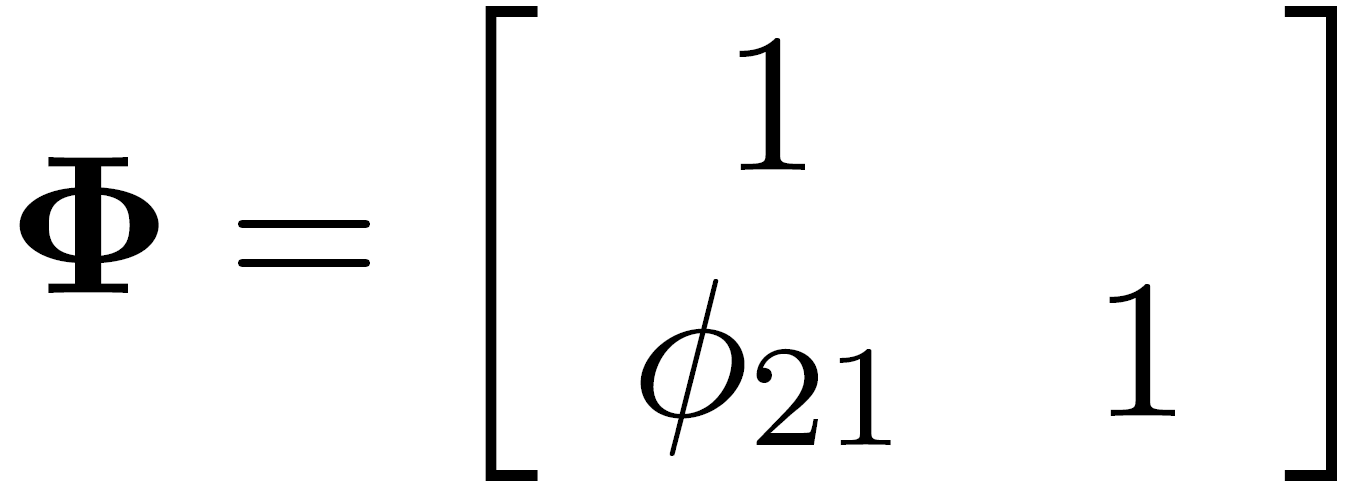
Theta: residual variance-covariance matrix
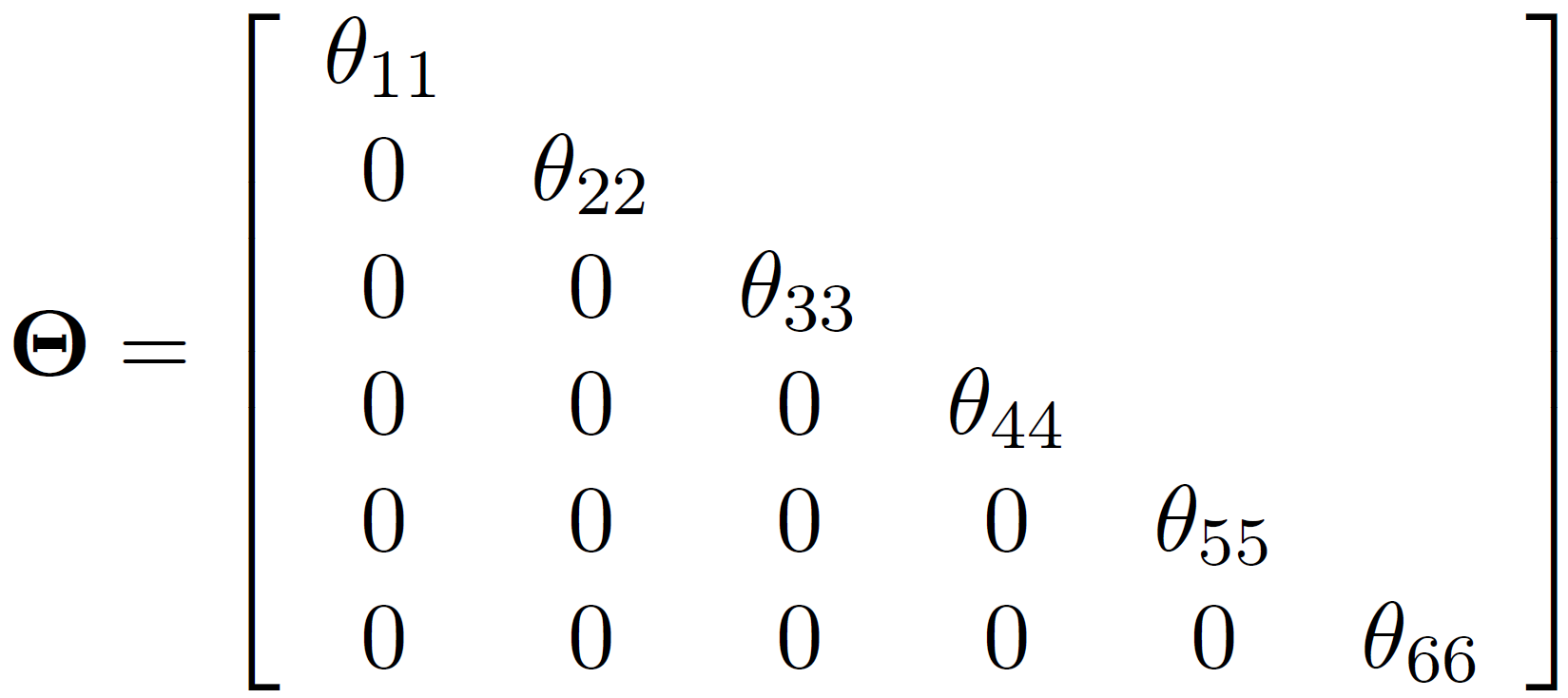
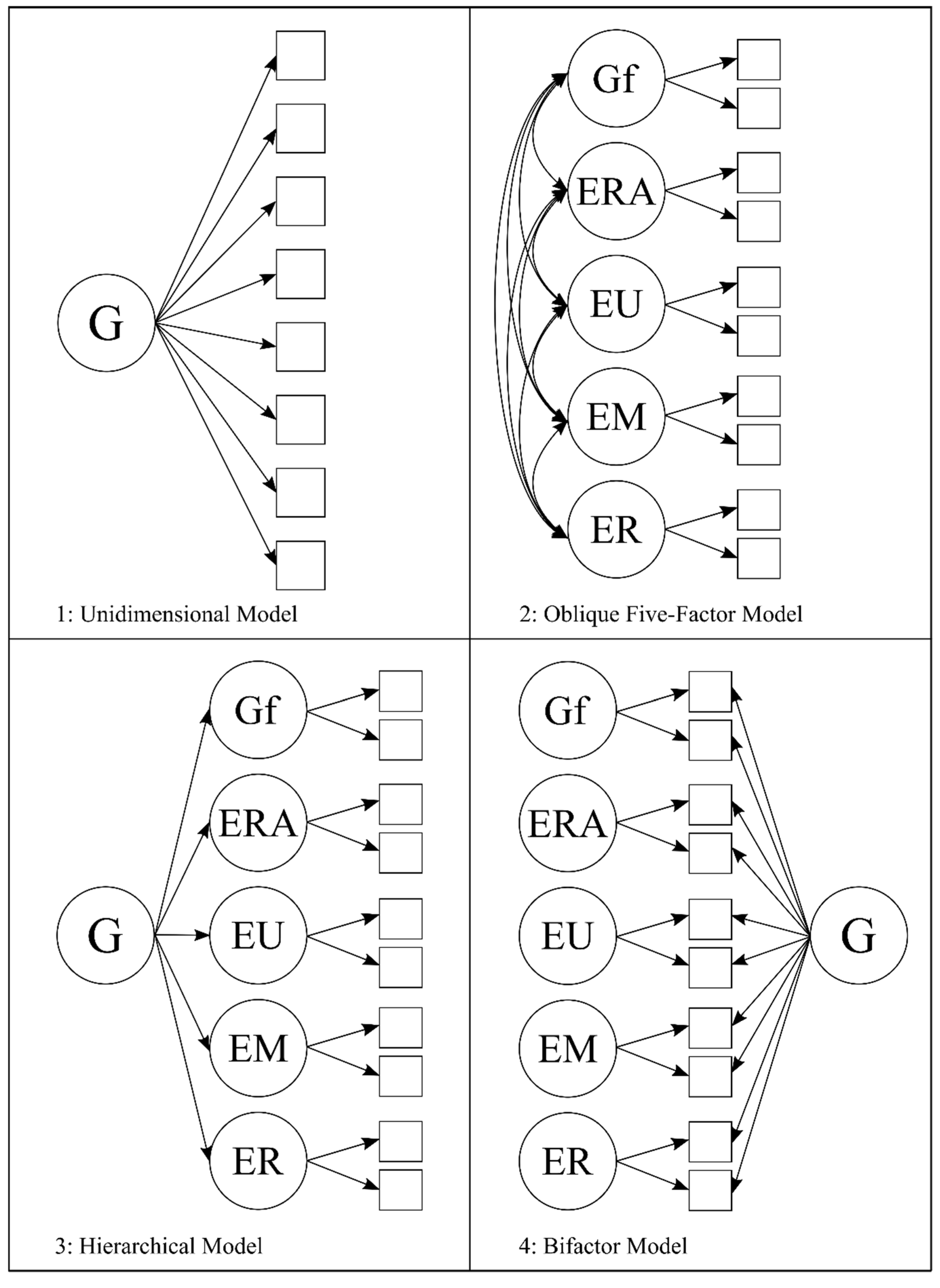
CFA “model families”
Key design choices:
- one factor vs multiple factors
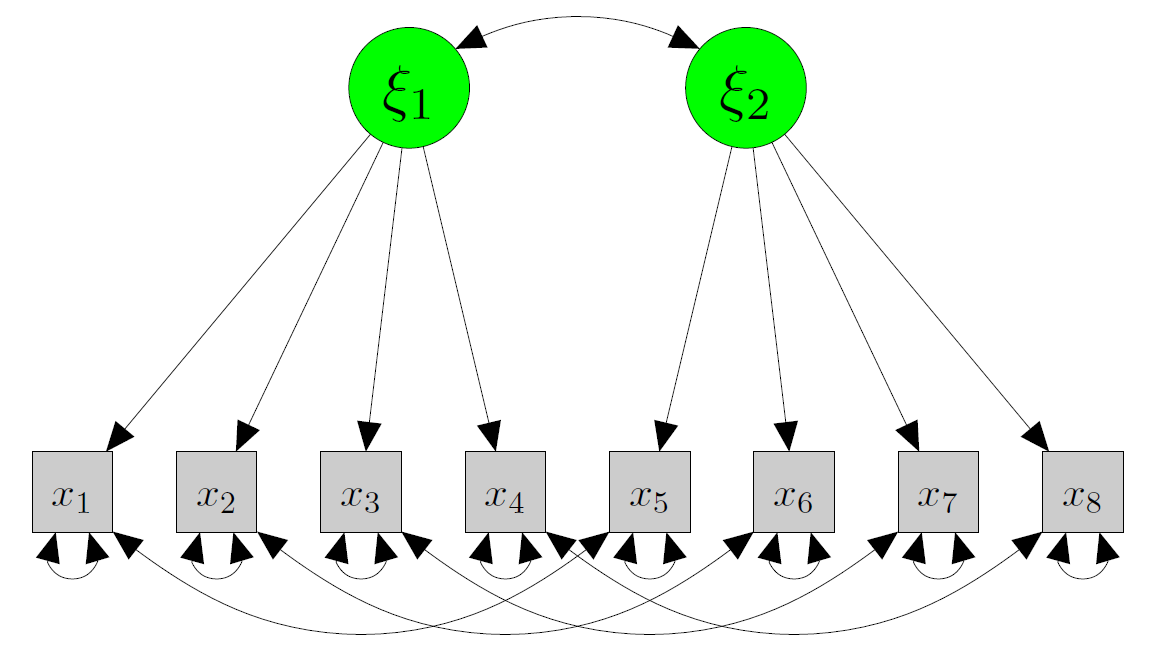
- are factors correlated?
- orthogonal vs oblique
- hierarchical / second-order?
- bifactor structure?
All have statistical and theoretical consequences.
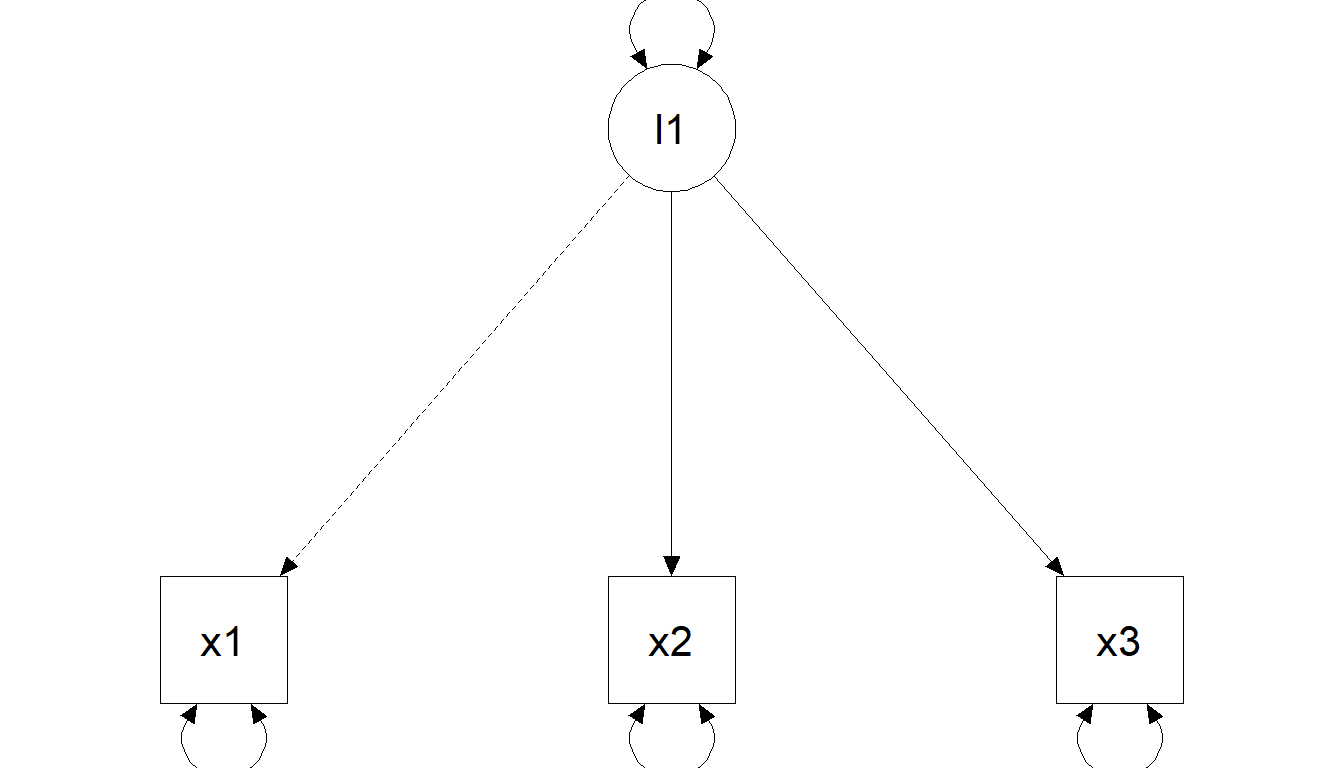
One-factor model
Two-factor model (correlated factors)
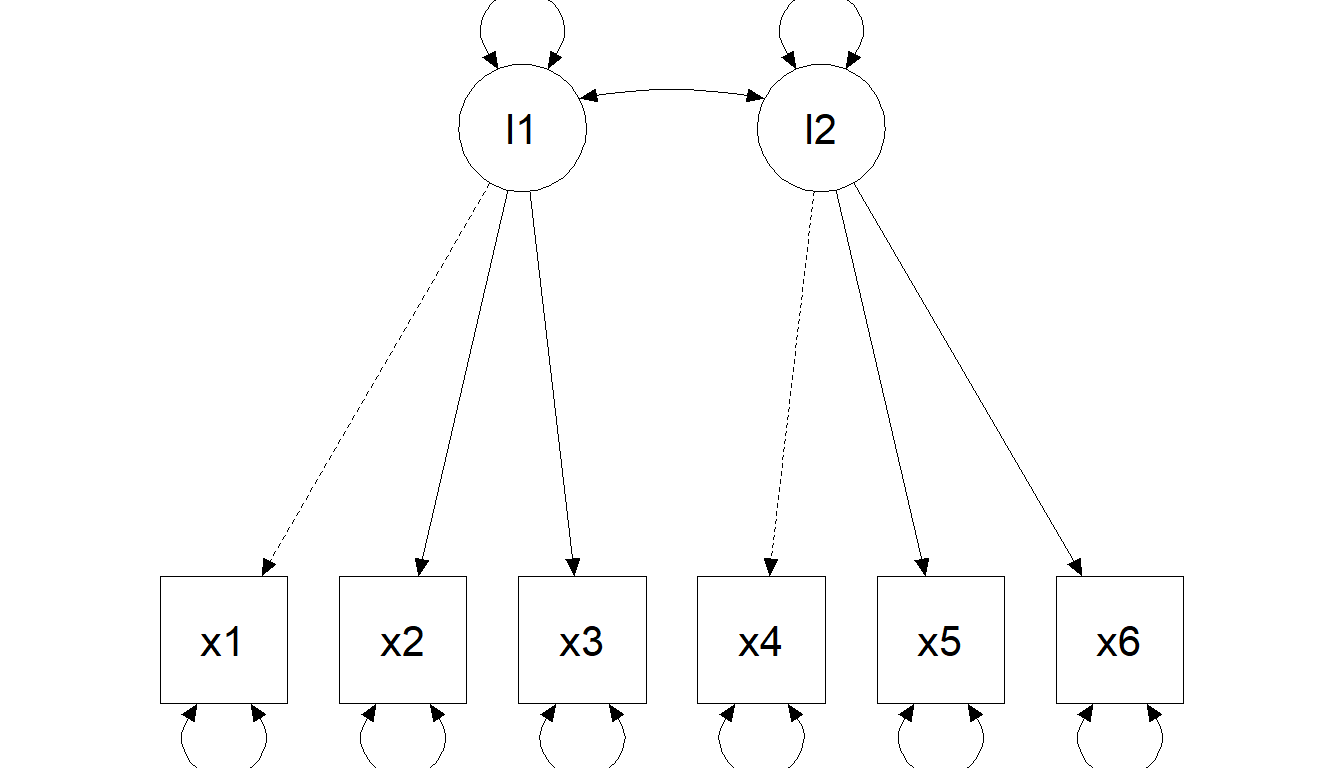
Two-factor model (orthogonal factors)
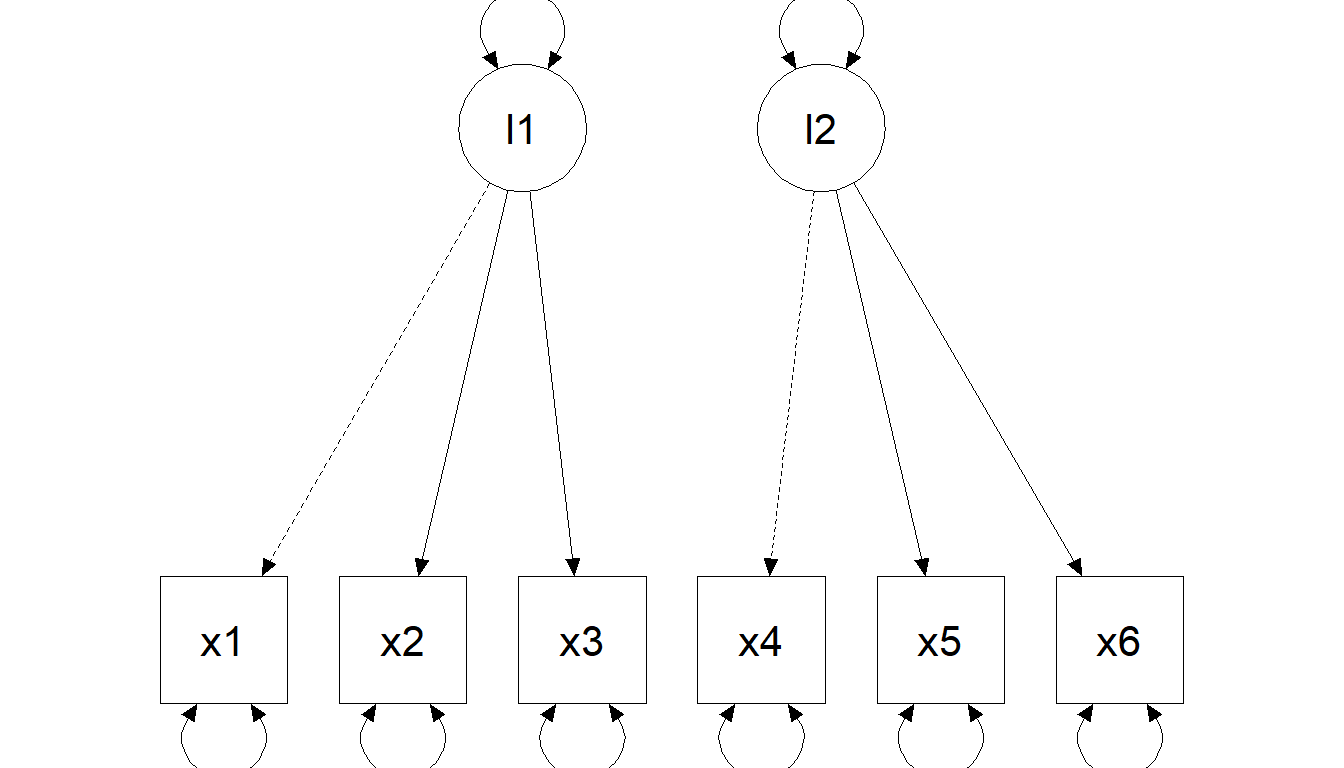
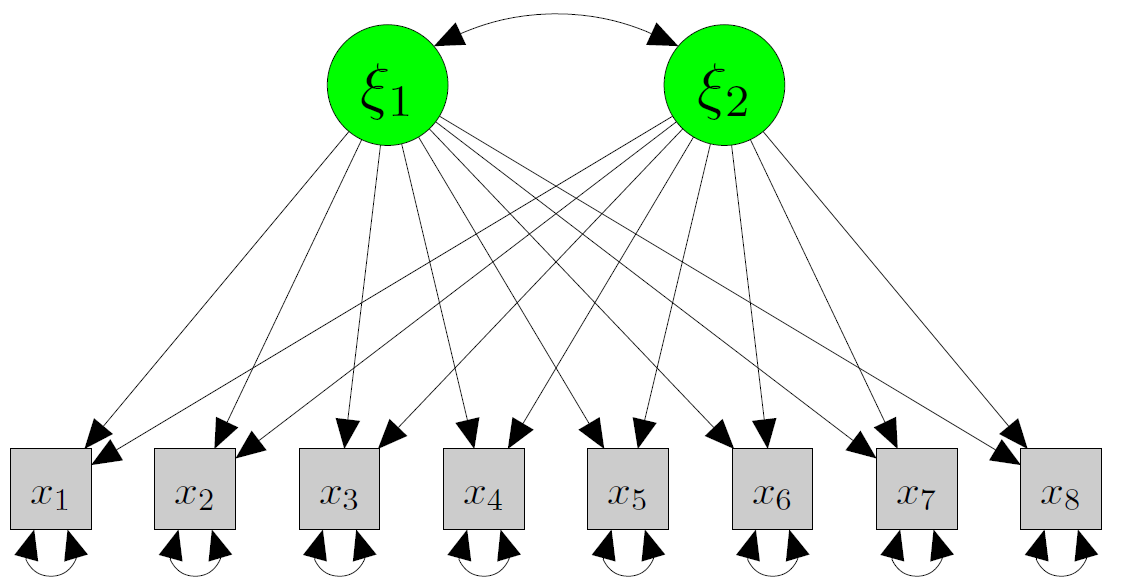
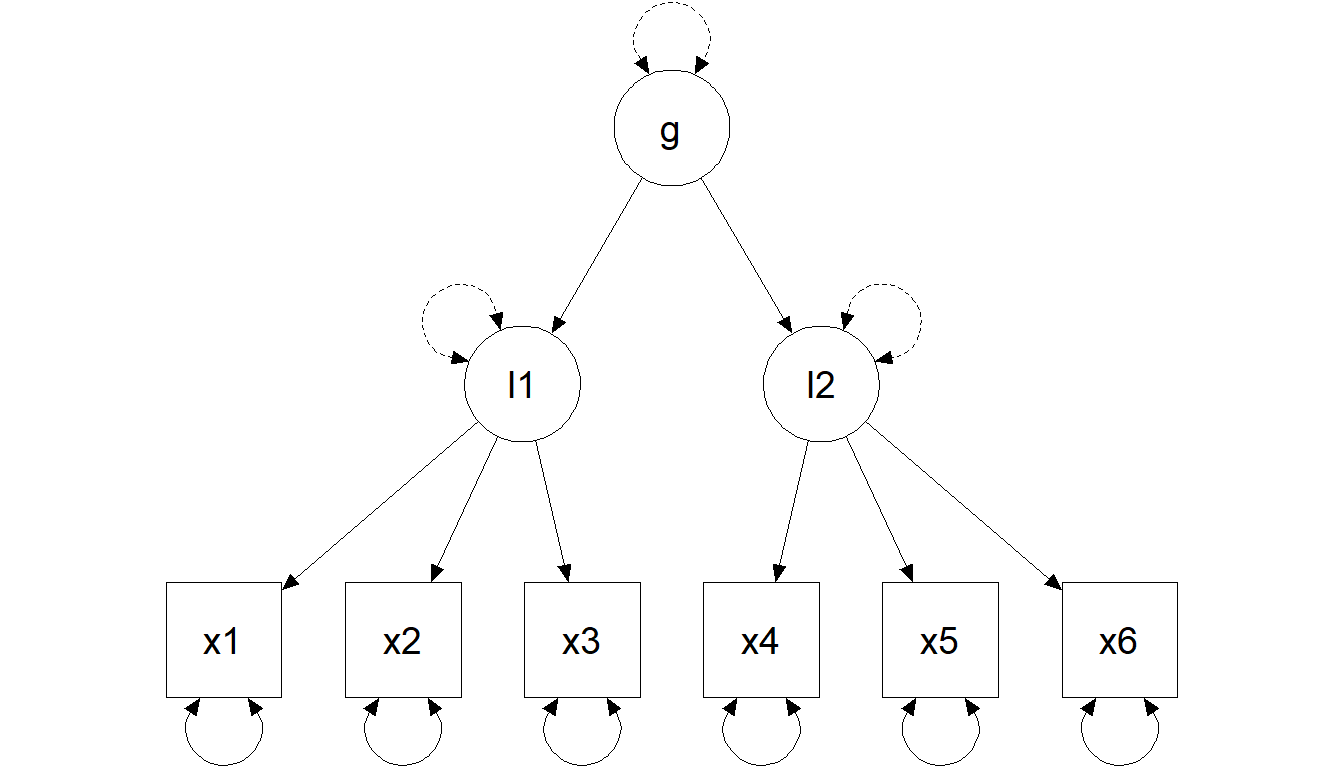
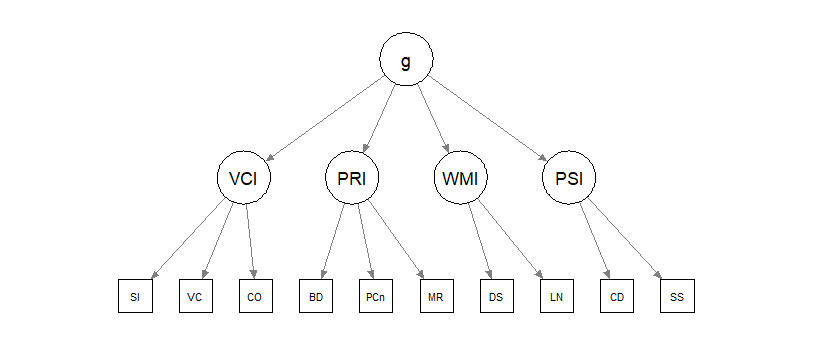
Hierarchical model (second-order factor)
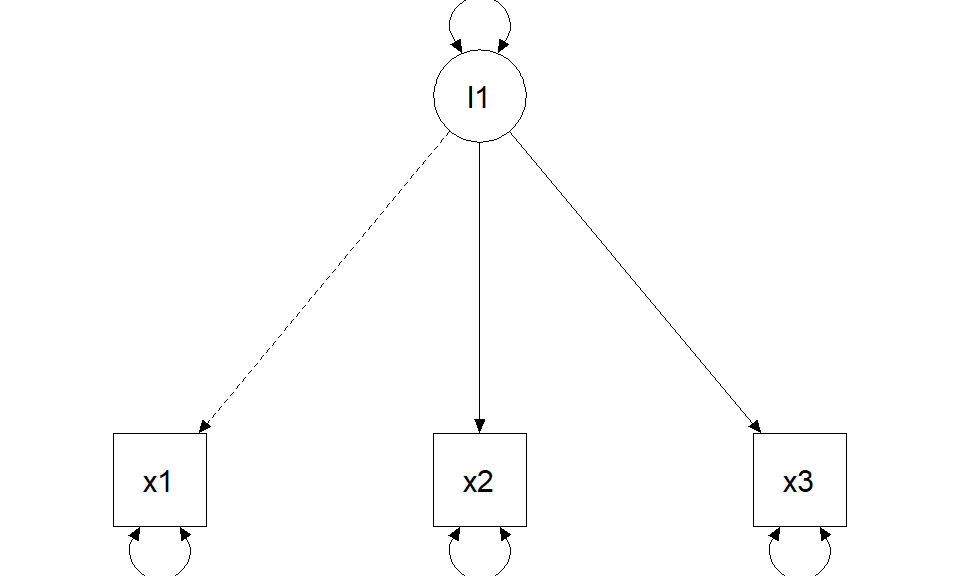
Constraints explained (marker vs standardization)
\[ \Sigma = \Lambda\Phi\Lambda' + \Theta \]
Marker method (fix one loading to 1)
Standardization (fix factor variance to 1)
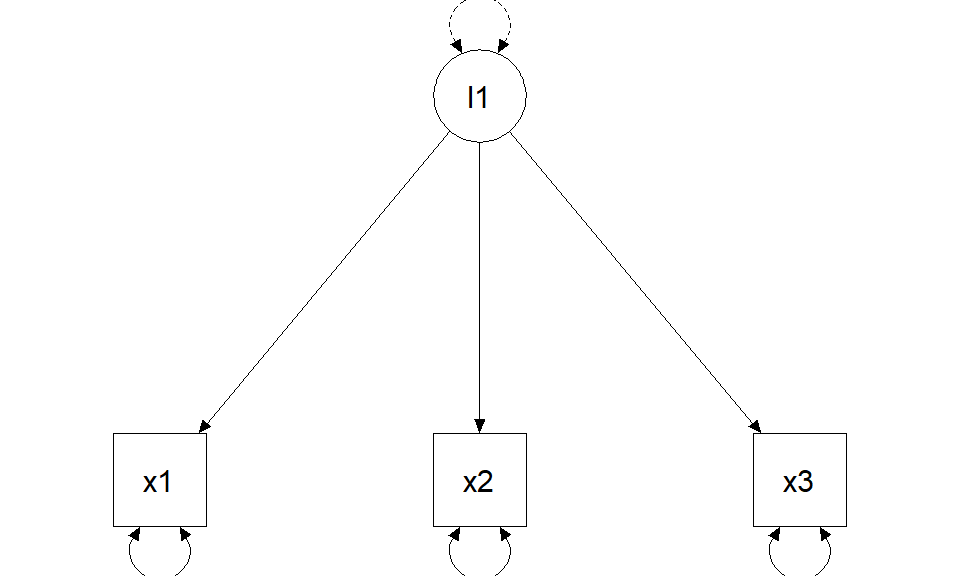
Note
Scaling changes the metric of unstandardized loadings, not the implied covariance model.
Graphical representation
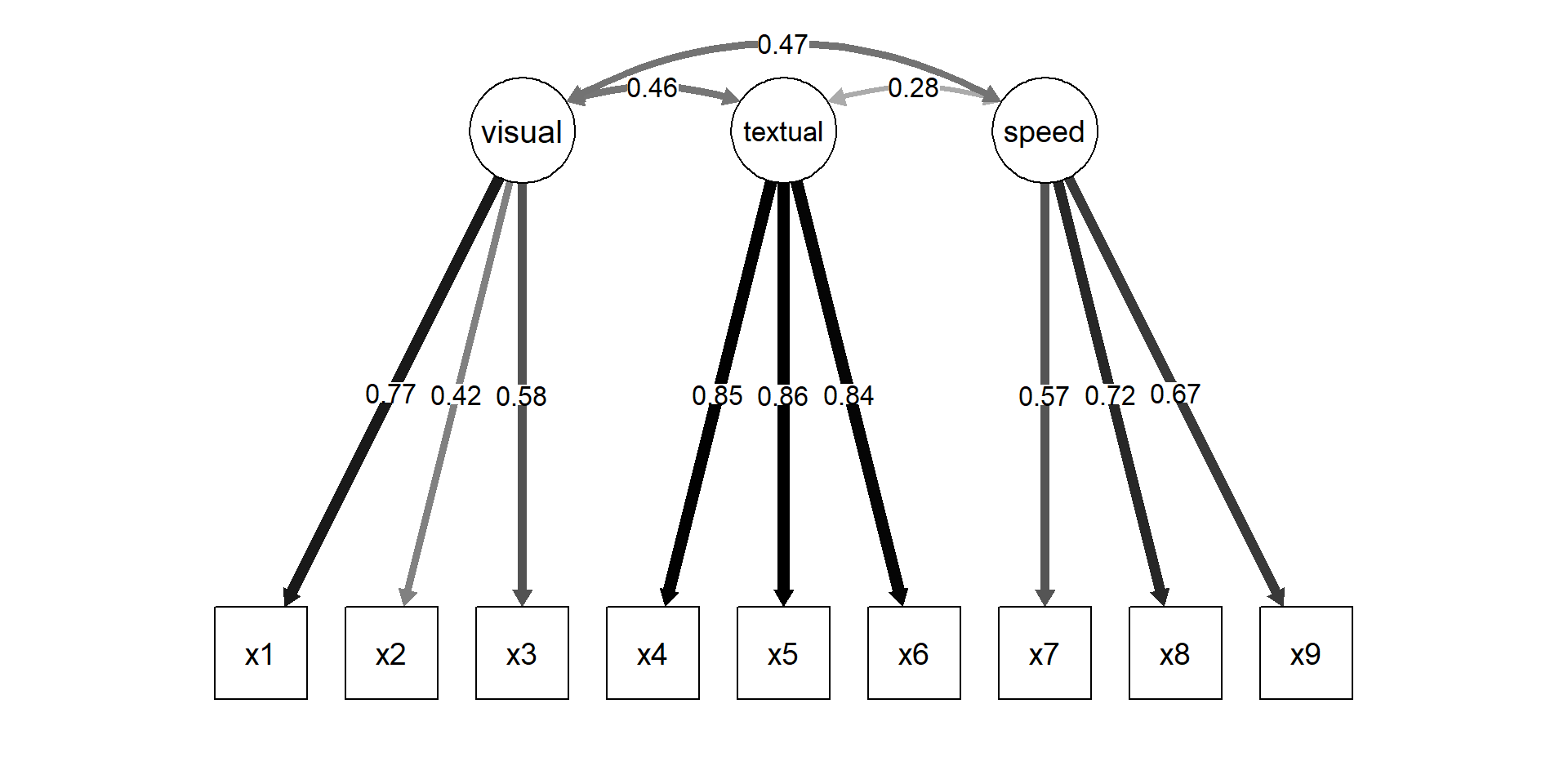
A hierarchical intelligence example
Theory: test scores are affected by specific abilities (e.g., processing speed) that are influenced by an overarching factor (\(g\)).
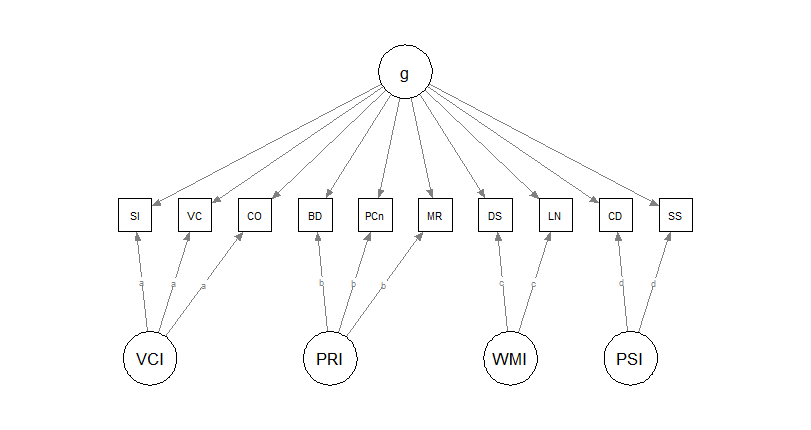
A second theoretical model: bifactor
Parallel theories: test scores are affected by a general factor (\(g\)) and by specific abilities that explain remaining variance.
All factors are set to be orthogonal.
Acknowledgments
Thanks to Massimiliano Pastore for his slides!

